
My research uses text and other high-velocity data sources to gain insight into the decision making of elites within American political institutions. I refine and train supervised machine learning models to measure political elites' psychological traits, fundamental economic preferences, and values from texts, such as the Congressional Record. This project has produced a book already in print. I also use unsupervised machine learning models to uncover the presentation strategies used by the White House to maintain the support of core supporters, as well as the issues on which presidential grassroots lobbying organizations focus as they engage in targeted appeals. I track variation in both over time to later test for their effects on the legislative agenda and the demographic composition of the presidential primary constituency. I supplement my text as data research by using federal data sources to create raters of regulatory significance for use in estimating the noteworthiness of federal regulatory initiatives.
I have published a book with the University of Chicago Press and another paper at PSRM which utilize supervised machine learning to process legislative text and generate measures of Big Five personality traits for members of the U.S. Congress, called ELUCIDATION scores. These publications are part of a larger collaborative project with Adam Ramey at NYU Abu Dhabi and Gary Hollibaugh at Notre Dame, which is focused on using supervised models to generate measures of elite personality traits, economic preferences, and values based on linguistic cues present in text data. The book, which was published in April 2017, describes the generation of ELUCIDATION scores and introduces a behavioral modeling framework for incorporating the Big Five personality traits, perhaps the most highly used typology of personality traits, into formal models. The book proceeds to revisit several aspects of congressional behavior, finding these traits have significant influence on legislative choices throughout the congressional lifespan. I have another paper at Political Behavior which finds evidence that citizens reward legislators with `valence' personality profiles more than legislators who are similar to themselves, and two published papers which test the implications of our modeling framework for Neuroticism and Openness to Experience, respectively.
The publication of the book has led me to turn my attention to training original text-based recognizers of traits, preferences, and values. ELUCIDATION scores are generated by processing the output of an existing text classifier to mitigate endogeneity concerns and add uncertainty estimates. My collaborators and I were awarded significant grants from the French ANR and NYU to train text-based recognizers of lower level facets within the Big Five construct, Moral Foundations Questionnaire scores, basic economic preferences through the Preference Survey Module, authoritarianism, the dark triad, and the Schwartz Values Survey. We have developed three working papers at various stages of development using the data. One paper presents predictive models trained using a variety of ML algorithms and assesses the performance of these models, and two papers use estimates from these models to investigate the role that legislators’ estimated Dark Triad traits and authoritarian values play in guiding their behavior in Congress.
The collaboration has also extended to several other projects which are applying the ELUCIDATION algorithm to other elite actors. I have a publication at the Journal of Law and Courts with Ramey and Hollibaugh along with Matthew E.K. Hall at Notre Dame which applied ELUCIDATION to U.S. Supreme Court concurrences to generate SCIPE (prounounced similarly to `Skype') scores for Supreme Court justices. Ramey, Hollibaugh, and I were invited to survey former Members of Congress in order to compare our estimates of legislator personalities with self-reported personality measures, and we have a working paper and an article at American Politics Research which finds that legislators report distorted estimates of legislators’ personalities from across the aisle, but fair estimates of their ideological dispositions. We are also collaborating with Astrid Hopfensitz at the Toulouse School of Economics to compare humans’ abilities to rank authors’ personalities using text with our machine learning models. Over the long term, we plan to extend our recognizer training and generation of legislator estimates to as many languages as possible, starting with French and Arabic because of existing funding interest.
Measuring Elite Personality Using Speech with Gary Hollibaugh and Adam Ramey (at Political Science Research and Methods).
Don't Know What You Got: A Bayesian Hierarchical Model of Neuroticism and Nonresponse with Gary Hollibaugh and Adam Ramey (at Political Science Research and Methods).
What I Like About You: Legislator Personality and Legislator Approval with Gary Hollibaugh and Adam Ramey (at Political Behavior).
Attributes Beyond Attitudes: Measuring Personality Traits on the Supreme Court with Matthew E.K. Hall, Adam Ramey, and Gary Hollibaugh (at Journal of Law and Courts).
Considerations in Personality Measurement: Replicability, Transparency, and Predictive Validity with Matthew E.K. Hall, Adam Ramey, and Gary Hollibaugh (at Journal of Law and Courts).
(Sympathy for) The Devil You Know? Openness, Risk Aversion, and the Incumbency Advantage with Adam Ramey and Gary Hollibaugh (at Frontiers in Political Science).
Still the Same? Revealed Preferences and Ideological Self-Perception Among Former Members of Congress with Gary Hollibaugh and Adam Ramey (at American Politics Research).
My presentation of the elite behavior in institutions project at Northwestern University's Kellogg School of Management for the Fifth Annual Text-as-Data Conference:

My primary solo research interest focuses on understanding the president's communication with core supporters using unsupervised machine learning on text data. I have collected eight years of email text sent by President Obama's grassroots lobbying organization, OFA, to his primary constituency, four years of emails from the Trump campaign to core supporters, and many months of email text sent by the Biden email list. I have analyzed this corpus using unsupervised machine learning techniques, particularly, the Topics over Time model, to uncover several strategies used by President Obama and Trump to emphasize common interest and trust with their base and measure variation in the mixture of these strategies used over time. I argue that these strategies should shift with economic conditions and political expectations, and themselves lead to change in the demographic makeup of a president's most fervent supporters. The collection of this corpus and comparable text data across multiple administrations and parties has required notable patience and investment, but with the 2021 presidential transition, the research agenda is well positioned now that comparisons may be made between the Obama, Trump, and Biden administrations going forward.
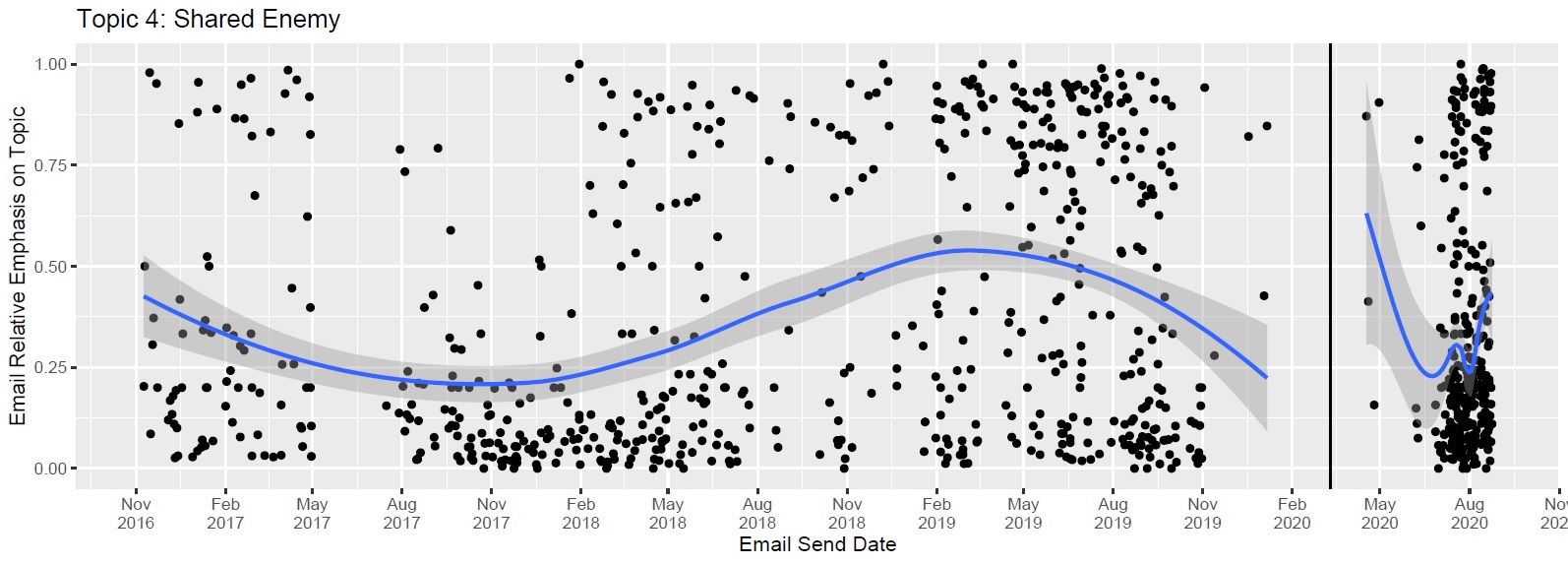
Though presidential grassroots lobbying organizations (PGLOs) like OFA have existed for over a decade, they are understudied, and I have a publication which describes OFA's use of email in the first seven years of the Obama administration and argues that the use of digital tools to 'go public' by presidents should be effective only among presidential copartisans in the public and Congress. I plan to build on this over the next few years with several other projects, leading into into a book on PGLOs. I have already been able to apply topic modeling using a high number of dimensions to my PGLO email dataset to develop measures of relative policy salience among the emails in this corpuss. I also have a working paper with a corresponding formal model of primary-focused public appeals, and I plan to test of the effect of PGLO events on electoral outcomes using coarsened exact matching (CEM), which will contribute to rounding out the planned book on PGLOs' influence on elections and agenda control. Beyond this larger project on PGLOs, I plan to continue to study the maintenance of the presidential primary constituency as technology develops, and when appropriate, extend my work to the primary constituencies of other actors.
Political Capital in the 21st Century: Presidential Grassroots Lobbying in the Obama Administration (at Congress and the Presidency).
Primary Constituency Focused Presidential Communication.
In a project with Fang-Yi Chiou, we estimate regulatory significance scores for a set of 39,311 regulations on the U.S. federal regulatory agenda between 1994 and 2019. This measurement effort leverages fifteen rater variables and an item response theory model to create continuous estimates of regulatory significance/noteworthiness for the entire set of rules with unique Regulatory Identification Numbers (RINs) during this 26 year period. Similar measures of significance for executive orders or bills rely on media-based raters, but only a small portion of regulations attract media attention. This project supplements media-based raters with large datasets parsed from the Unified Agenda, Regulations.gov, and the Federal Register to develop broad-based measures of significance which can be updated frequently in the future. Our manuscript leverages the continuous significance scores to test the implications of a simple model of agency productivity in which the executive and/or the legislative branches possess an informal veto over agency rulemaking, and finds that the executive branch holds greater influence over moderately significant rules, while Congress holds greater influence over the most significant regulations. We plan to update this dataset over time to provide scholars significance estimates for new regulations as they are reported by federal agencies.
I also use survey data and causal inference methods to study the effects of military service on political attitudes, as volunteer veterans are highly over-represented among political elites but the extant data on this group has been poor. I have administered the Survey of American Veterans (SAVe) with Tyson Chatagnier at the University of Houston, and we applied CEM to these data to uncover treatment effects of military service on political attitudes in a paper currently under review. In a previously published article we found that veterans of the All Volunteer Force are generally more conservative than those who did not serve, but the CEM revealed that military service is associated only with more nationalism, not general conservatism. We administered a second wave of the SAVe in summer 2017 to further articulate and confirm this nationalist causal effect of service.
Would You Like to Know More? Selection, Socialization, and the Political Attitudes of Military Veterans at Political Research Quarterly with with J. Tyson Chatagnier.
Are You Doing Your Part? Veterans' Political Attitudes and Heinlein's Conception of Citizenship at Armed Forces and Society with J. Tyson Chatagnier.
The Development of Political Attitudes and Behaviour Among Young Adults at the Australian Journal of Political Science with Richard G. Niemi.